
Ученые Университета Сунгюнгван в Южной Корее создали человекоподобную систему памяти, которая улучшает производительность трансформеров — моделей машинного обучения, используемых для обработки текстов на естественном языке и лежат в основе диалоговых платформ, таких как ChatGPT. Результаты исследования опубликованы в препринте статьи на сайте arXiv.
Трансформер представляет собой тип архитектуры глубокого обучения, который основан на механизмах, имитирующих когнитивное внимание. При обучении нейронная сеть определяет корреляции между различными словами в текстах (взятых, например, из «Википедии»), что позволяет ей генерировать собственные тексты. В отличие от рекуррентных нейронных архитектур, которые обрабатывают текст последовательно, трансформеры делают это параллельно.


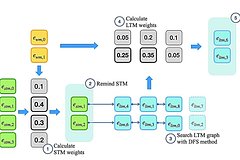
Однако трансформеры сталкиваются с трудностями при обучении на длинных последовательностях из-за ограничений в емкости. Для решения этой проблемы ученые воспользовались тем фактом, что в отличие от нейронных сетей, которые обрабатывают весь текст, люди выделяют из текстов только релевантную информацию, откладывая ее в кратковременной и долговременной памяти, чтобы воспроизвести в будущем. Теория Хебба объясняет, как мозг формирует нейронные связи для запоминания и извлечения информации:
Согласно теории Хебба, которая объясняет, как мозг формирует связи между нейронами для хранения и извлечения информации, многократная одновременная активация двух нейронов укрепляет связь между ними. Новая система памяти, называемая Memoria, извлекает и хранит информацию, называемой энграммой, на нескольких уровнях (рабочая, кратковременная и долговременная память), используя коэффициенты, соответствующие силе связи между нейронами, которые изменяются в соответствии с теорией Хебба.
Серия экспериментов показала, что Memoria значительно повышает производительность трансформеров при выполнении различных задач, связанных с обработкой длинных последовательностей данных. Авторы пишут, что она улучшает способность учитывать долгосрочные закономерности в различных задачах и превосходит существующие методологии в сортировке и языковом моделировании, а также классификации длинных текстов.