Усы, лапы и хвост Созданный Google искусственный интеллект научился различать котов

Исследуя алгоритмы машинного обучения, ученые из Google построили самую крупную в мире нейронную сеть, предназначенную для анализа изображений. После нескольких дней работы система научилась распознавать лица людей, некоторые части тел и... кошек. В этом, впрочем, нет ничего удивительного - систему тренировали на кадрах из случайных роликов, взятых с YouTube. Там, как известно, этих самых кошек - выше крыши.
Машина и учитель
Термин "искусственный интеллект" придумал создатель языков программирования ALGOL и LISP Джон Маккарти в 1955 году. Это было прекрасное и наивное время - люди недооценивали сложность собственного мозга и отчаянно переоценивали возможности компьютеров. Казалось, еще чуть-чуть и появятся машины, которые будут умнее и быстрее самого человека (и, как следствие, истребят человечество). Шли годы, компьютеры усложнялись, а искусственного интеллекта так и не появилось. Как оказалось, компьютер нельзя научить полноценно мыслить (по крайней мере, пока), однако натренировать его на выполнение каких-то осмысленных аналитических операций очень даже можно.
Раздел теории искусственного интеллекта, занимающийся такими вот обучающимися алгоритмами, получил название машинного обучения. Нужно понимать, что машинное обучение - это хорошо развитая прикладная наука, использующая самые современные методы анализа, статистики и многих других разделов математики. Машинное обучение используется при создании систем распознавания изображений, голоса, анализа текста, а также спам-фильтров. Мы поговорим лишь об одном классе алгоритмов, известном как обучение с (частичным) привлечением учителя.

На этой картинке непросто распознать суслика и ослика. Этому мешает, среди прочего, наличие паукана
Lenta.ru
Основная идея, стоящая за этим термином, довольно проста: для того чтобы отличать некоторые объекты - скажем, ослика от суслика - вовсе не обязательно знать про них очень много. Представим, что мы хотим научить человека, никогда в жизни не видевшего ни первого, ни второго, различать этих животных на картинках. Мы можем действовать в лоб: попытаться объяснить, что такое осел, затем объяснить, что такое суслик, и предоставить аналитическому аппарату этого человека решать, что же изображено на той или иной картинке.
С другой стороны, есть менее "человеческий" способ: надо показать человеку, скажем, 100 фотографий сусликов и 100 фотографий ослов, предоставив ему возможность самому разобраться в отличиях
двух животных. В этом случае, конечно, наш подопечный не сможет охарактеризовать каждое животное по отдельности, однако с задачей различения справится, возможно, не хуже.
Ключевым моментом здесь является то, что картинки с животными нам придется заготовить заранее. Например, если мы пытаемся натренировать программу на распознавание лиц, то для обучения потребуется множество изображений, часто заранее обработанных (для анализа, например, бывает удобно, чтобы лица были обведены контурами - так алгоритмам удобнее работать). Это, разумеется, крайне осложняет жизнь учителей - ведь кто-то должен все эти фото просмотреть и подготовить их к потреблению алгоритмом.
Бороться с этой трудностью помогает частичное устранение учителя, то есть в процесс обучения добавляется домашняя работа. Это означает, что в упомянутом выше примере с сусликами и осликами помимо множества отсортированных и готовых к потреблению данных имеется случайное множество картинок с разными животными. Прежде чем перейти к обучению, ученику предлагается подготовиться самому - посмотреть на картинки, поискать среди них одинаковые, возможно, сообразить, чем одни изображения отличаются от других. В результате основная часть обучения пойдет (по крайней мере, должна пойти) быстрее.
Для того чтобы показать, почему такой подход действительно работает, нужно пояснить, как вообще обучающиеся системы реализованы на практике. В частности, мы поговорим об искусственных нейронных сетях.
Искусственные нейронные сети
С точки зрения математики, такая сеть - это граф, каждому направленному ребру которого приписан вес, а на вершинах заданы так называемые функции активации (подробно о графах "Лента.ру" уже писала). Если коротко, то граф - это множество точек, соединенных ребрами. Граф называется ориентированным, если на ребре задано направление, и взвешенным, если каждому ребру присвоено некоторое число, именуемое весом. Пример взвешенного графа - схема метро. Там в качестве весов выступает, например, время, которое тратится на поездку от одной станции до следующей.
Граф нейронной сети разбит на уровни, причем ребра ведут с уровня, имеющего больший номер, на уровень с меньшим номером. Верхний, называемый еще уровнем входа, состоит из нейронов, на которые подаются входные сигналы. Затем идут (возможно) несколько скрытых нейронов, а заканчивается все нижним уровнем - уровнем вывода. Распространением по сети сигнала управляют функции активации (каждой вершине графа соответствует собственная функция) - по заданному весу ребра и входному сигналу, пришедшему в вершину, такая функция вычисляет выходной сигнал, который пойдет по этому ребру.
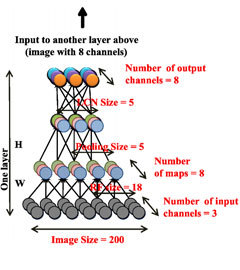
Схема нейронной сети. Иллюстрация авторов исследования (Нажмите, чтобы увеличить)
Lenta.ru
Веса ребер называются свободными параметрами системы. Суть процесса обучения состоит в автоматическом выборе значений этих параметров таким образом, чтобы полученная в результате нейронная сеть работала лучше. В каком смысле лучше, удобно пояснить на примере алгоритма с учителем для случая распознания образов (хотя принципиально задачи распознавания речи и текста от этой ничем не отличаются).
Сначала каждое изображение из обучающего множества представляется в виде вектора очень большой размерности, у которого компонент столько, сколько пикселей в картинке. Значение соответствующей компоненты обычно равно ее цвету - традиционно для анализа используют черно-белые изображения, поэтому цвет вполне можно задавать одним числом. Например, если разрешение картинки составляет 640 на 480 точек, то работать системе при лобовом подходе придется в 307200-мерном пространстве параметров. Чтобы свести количество параметров к разумному, ученые обычно используют разного рода уловки. Например, метод главных компонент - метод, который позволяет уменьшить размерность вектора с минимальными потерями.
Как бы то ни было, но вектор (возможно, уменьшенный) подается на вход сети, после чего результат работы искусственного интеллекта сравнивают с правильным ответом. В случае распознавания образов ответ состоит из одного числа, соответствующего названию объекта (например, 0 - суслик, а 1 - ослик, причем, как уже говорилось, эти ответы приходится готовить заранее другими методами). Разница между правильным ответом и ответом, полученным сетью, называется ошибкой обучения. Свободные параметры сети после прогонки подправляются таким образом, чтобы эту ошибку минимизировать. При этом речь идет, конечно, о минимизации в среднем - это связано с тем, что задача покомпонентной минимизации, то есть нахождения такого набора весов, чтобы для всех элементов обучающего множества ошибка была равна нулю, вполне может оказаться неразрешимой. Например, такое вполне может произойти из-за строения самого графа нашей сети.
Самым оптимальным, конечно же, было бы прогнать все элементы множества, используемого для обучения, посчитать все ошибки и только после этого выбирать веса. Это, однако, совершенно неподъемная задача, поэтому правки в веса вносятся после изучения каждого примера. Говоря формально, используется метод градиентного спуска для решения некоторой задачи минимизации среднего квадратичного отклонения.
Теперь легко понять, как выглядит задача обучения с домашним заданием. В систему добавляются некоторые дополнительные параметры, которые ускоряют процесс обучения (например, тот же метод градиентного спуска). Чтобы вычислить эти параметры, используются данные без правильных ответов, для анализа которых используются статистические методы, реализованные, возможно, не только нейронной сетью.
Самообучающееся обучение
В 2007 году ученые из Google (и по совместительству из Стэнфорда) предложили модификацию алгоритма с частичным присутствием учителя, который они назвали алгоритмом "самообучающеегося обучения" (self-taught learning, pdf). Они заметили, что домашнее задание в существовавших на тот момент алгоритмах предполагается связанным с основным процессом обучения. То есть, например, если мы учимся распознавать животных, то в изображениях из домашнего задания тракторов и мотоциклов не будет.
С одной стороны, такой подход кажется логичным, однако ученые из Google задались вопросом: быть может, пользу принесет и домашнее задание, не связанное непосредственно с той задачей, в решении которой упражняется программа? Вдруг, например, звуки природы позволят более эффективно распознавать человеческую речь? Среди прочего, они мотивировали свой вопрос еще и такими неформальными рассуждениями: в человеческом мозгу порядка 1014 синапсов, а время жизни типичного Homo Sapiens - порядка 109 секунд. Считая, что синапсы образуются в результате обучения и каждому из них соответствует всего один бит информации, получаем, что в среднем в секунду человек выучивает порядка 105 бит информации.
При всей уязвимости этой аргументации, разумное зерно в ней есть: вероятно, значительная часть обучения происходит без участия самого человека на основе неотсортированных данных, которые, возможно, и не были связаны с исходной задачей. Более того, например, в задаче распознавания образов пользу от предварительной подготовки можно указать явно. Вполне может случиться, что после такой подготовки система начнет анализировать изображение не только на основе набора пикселей, но и по "мазкам" - резким ярким продолговатым пятнам, образующим контур в изображении с высокой контрастностью. Эти объекты, по словам ученых, относятся к более высокому уровню анализа изображений, нежели отдельные пиксели или просто светлые пятна неопределенной формы.
Результаты Google и коты
В новой работе (pdf), приуроченной к 29-й конференции по машинному обучению в Эдинбурге, ученым впервые удалось применить свои идеи на практике и доказать, что их подход действительно работает. В эксперименте использовалось 1000 серверов с примерно 16 тысячами ядер. Всего полученная нейронная сеть содержала примерно 3 миллиона нейронов и 1,15 миллиарда синапсов. Для сравнения, до этого в экспериментах по машинному обучению применялись только сети с 1-10 миллионами связей.

Представление о кошке, полученное нейронной сетью Google. Изображение из блога Google
Lenta.ru
В качестве неотсортированного обучающего множества было взято 10 миллионов скриншотов различных случайных видео с YouTube. При работе нейронной сети каждый скриншот обрабатывался серией фильтров, прежде чем непосредственно подвергнуться анализу. В результате такой обработки каждая картинка сводилась к изображению 200 на 200 пикселей.
При построении сети ученые исходили из гипотезы локальной связности - они предполагали, что каждый нейрон соединен лишь с небольшим количеством соседних. Это предположение вполне разумно, если учесть, что нейронная сеть в человеческом мозгу именно так и устроена. Кроме этого, ученые опирались на результаты нейробиологов об анализе изображений человеком - они полагали, что изображение не анализируется целиком. Вместо этого оно разбивалось на пересекающиеся куски 16 на 16 пикселей, каждый из которых подвергался анализу отдельно.
После трех дней интенсивной самоподготовки сети ученые проверили результаты. Оказалось, что система не только научилась распознавать технические нюансы, наподобие уже упоминавшихся "мазков". Совершенно самостоятельно нейронная сеть научилась различать объекты сложной природы, например, человеческие лица, части тел, пешеходов на улицах. Более того, немного подучив систему с помощью уже отсортированных данных, ученые добились точности распознавания в 15,8 процента, что является колоссальным рывком в сравнение с прежними 9,3 процента для самых совершенных из существующих систем. Впрочем, в новости нейросеть от Google попала вовсе не из-за масштабности и необычности результатов. Дело в том, что в результате изучения скриншотов с YouTube система самостоятельно научилась распознавать котов (подтвердив тем самым стереотипы, связанные с этим видео-сервисом).
Повсеместное развитие новой концепции останавливает, однако, высокая вычислительная сложность нейронных сетей. Это, конечно, временно: решить эту проблему поможет дальнейший рост мощностей, а также создание компьютеров с архитектурами, "заточенными" под нейронные сети (работы в этом направлении ведутся, например, в Intel - там создают нейроморфные чипы). Главный вывод, однако, который можно вынести из нового достижения ученых: самостоятельные занятия крайне полезны. Даже если ты программа, предназначенная для распознавания кошек.