

Ученые Гарвардского университета (США), Нагойского университета и Медицинской школы Университета Кэйо (Япония) доказали сходство между обучением животных и типом машинного обучения, называемым обучением временной разнице (англ. temporal difference, TD). В статье, опубликованной в журнале Nature Neuroscience, исследователи продемонстрировали, что дофаминергические нейроны реализуют биологический аналог функции ошибки в алгоритме TD.
Обучение временной разнице — это тип обучения, при котором сначала создается модель, предсказывающая наступление какого-либо события в будущем, а потом эта модель корректируется с течением времени. Например, модель, которая предсказывает погоду в субботу по погоде в понедельник, корректируется с учетом погоды в пятницу, когда можно сделать более точный прогноз на субботу. Важную роль в этом алгоритме, как и в обычном обучении, играет функция ошибки, которая сообщает о разнице между ожиданием и реальностью, однако в алгоритме TD ошибка может вычисляться для каждого момента времени между первым стимулом и вознаграждением.


В конце XX века нейробиологи увидели, что у обучающихся животных частота возбуждения дофаминовых нейронов, расположенных в таких областях мозга, как вентральная область покрышки и черная субстанция, имитирует функцию ошибки в алгоритме TD. В начале обучения животное не связывает стимул с последующим вознаграждением в виде вкусной еды, поэтому при получении пищи дофаминовые клетки резко увеличивают частоту возбуждения. Со временем это усиление начинает происходить все раньше и раньше, пока не достигает стимула, надежно предсказывающего вознаграждение. Когда животное обучено, вознаграждение уже не вызывает усиленную работу нейронов. Однако многие исследования не смогли подтвердить, что дофаминовые сигналы действительно воспроизводят алгоритм TD.
Исследователи подробно изучили динамику дофамина во время ассоциативного обучения мышей. Для этого они ввели в вентральную часть полосатого тела, куда тянутся аксоны дофаминергических нейронов, аденоассоциированный вирусный вектор, несущий ген сенсора GRAB(DA2m). При связывании с дофамином сенсор начинает испускать флуоресцентный сигнал, который измеряли оптоволоконным флуориметром. Мышей обучали ассоциировать запах с вознаграждением водой, при этом стимул длился одну секунду, а задержка перед вознаграждением — две секунды. Со временем дофаминовые сигналы усиливались в ответ на запах, при этом уменьшаясь в ответ на вознаграждение. У каждого животного ученые наблюдали сдвиг пика активности дофамина на 3,5 миллисекунды за каждое из нескольких сотен испытаний.
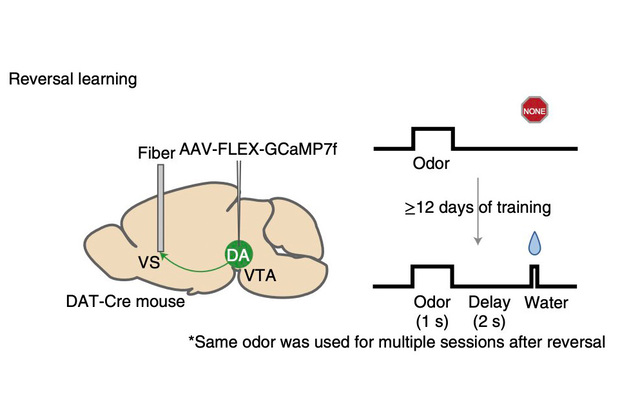
Схема эксперимента с реверсивным обучением
При реверсивном обучении проверяется, может ли животное, которое уже было обучено связывать определенный стимул с вознаграждением, перестать реагировать на этот стимул, который уже не связан с вознаграждением, и обучиться новой ассоциативной связи. Изображение: Amo et al.
На втором этапе исследования ученые проверили, будет ли наблюдаться временной сдвиг дофаминовых сигналов при реверсивном обучении. Для этого животных обучали классической задаче запах-вознаграждение в течение 12 дней, а затем меняли первоначальный стимул на другой запах. Дофаминовый сигнал также продемонстрировал временной сдвиг в течение периода задержки, но с более высокой скоростью. То же самое наблюдалось, когда мыши не получали ожидаемого вознаграждения; в этом случае сдвигающийся назад дофаминовый сигнал в виде впадины соответствовал отрицательной TD-ошибке.
Результаты исследования, подтверждающие сходство между работой дофаминовых нейронов и ТD-алгоритмом, позволяют лучше понять, каким образом в мозге реализуются алгоритмы обучения, основанные на вознаграждении, и насколько они похожи на те алгоритмы, что используются в машинном обучении. В будущем это поможет разработать новые, более эффективные методы разработки искусственного интеллекта.